Download
Note
Run these commands in a Jupyter notebook (or other IDE), ensuring you are in your mapreader python environment.
Note
You will need to update file paths to reflect your own machines directory structure.
Note
If you already have your maps stored locally, you can skip this section and proceed on to the Load part of the User Guide.
MapReader’s Download subpackage is used to download maps stored on as XYZ tile layers on a tile server.
It contains two classes for downloading maps:
SheetDownloader - This can be used to download map sheets and relies on information provided in a metadata
jsonfile.Downloader - This is used to download maps using polygons and can be used even if you don’t have a metadata
jsonfile.
MapReader uses XYZ tile layers (also known as ‘slippy map tile layers’) to download map tiles.
In an XYZ tile layer, each tile in is indexed by it’s zoom level (Z) and grid coordinates (X and Y). These tiles can be downloaded using an XYZ download url (this normally looks something like “https://mapseries-tilesets.your_URL_here/{z}/{x}/{y}.png”).
Regardless of which class you will use to download your maps, you must know the XYZ URL of your map tile layer.
SheetDownloader
To download map sheets, you must provide MapReader with a metadata file (usually a json file), which contains information about your map sheets.
Guidance on what this metadata json should contain can be found in our Input Guidance.
An example is shown below:
{
"type": "FeatureCollection",
"features": [{
"type": "Feature",
"geometry": {
"geometry_name": "the_geom",
"coordinates": [...]
},
"properties": {
"IMAGE": "101602026",
"WFS_TITLE": "Nottinghamshire III.NE, Revised: 1898, Published: 1900",
"IMAGEURL": "https://maps.nls.uk/view/101602026",
"YEAR": 1900
},
}],
"crs": {
"name": "EPSG:4326"
},
}
To set up your sheet downloader, you should first create a SheetDownloader instance, specifying a metadata_path (the path to your metadata.json file) and download_url (the URL for your XYZ tile layer).
This is done using:
from mapreader import SheetDownloader
my_ts = SheetDownloader(
metadata_path="path/to/metadata.json",
download_url="mapseries-tilesets.your_URL_here/{z}/{x}/{y}.png",
)
e.g. for the OS one-inch maps:
#EXAMPLE
my_ts = SheetDownloader(
metadata_path="~/MapReader/mapreader/worked_examples/persistent_data/metadata_OS_One_Inch_GB_WFS_light.json",
download_url="https://mapseries-tilesets.s3.amazonaws.com/1inch_2nd_ed/{z}/{x}/{y}.png",
)
To help you visualize your metadata, the boundaries of the map sheets included in your metadata can be visualized using:
my_ts.plot_all_metadata_on_map()
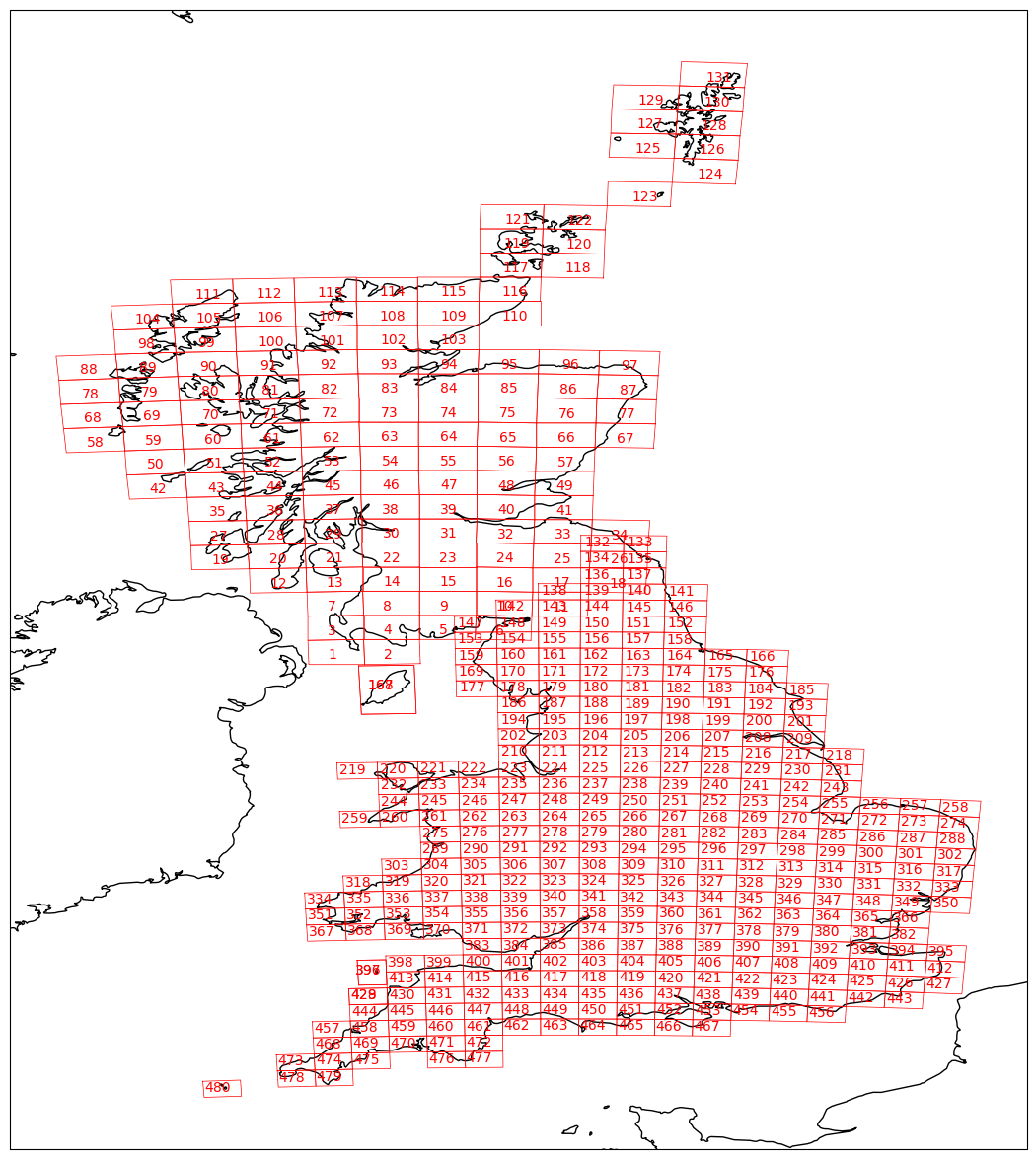
The add_id argument can be used to add the WFS ID numbers of your map sheets on the resulting plot.
This can be helpful in identifying the map sheets you’d like to download.
It can also be helpful to know the range of publication dates for your map sheets.
This can be done using the .extract_published_dates() method:
my_ts.extract_published_dates()
By default, this will extract publication dates from the "WFS_TITLE" field of your metadata (see example metadata.json above).
If you would like to extract the dates from elsewhere, you can specify the date_col argument:
my_ts.extract_published_dates(date_col=["properties", "YEAR"])
This will extract published dates from the "YEAR" field of your metadata (again, see example metadata.json above).
Note
If your metadata.json is a multilayer dictionary, you will need to pass the key for each layer as a separate item in list form.
These dates can then be visualized, as a histogram, using:
my_ts.hist_published_dates()
Your SheetDownloader instance (my_ts) can be used to query and download map sheets using a number of methods:
1. Any which are within or intersect/overlap with a polygon. 1. Any which contain a set of given coordinates. 2. Any which intersect with a line. 3. By WFS ID numbers. 4. By searching for a string within a metadata field.
These methods can be used to either directly download maps, or to create a list of queries which can interacted with and downloaded subsequently.
Query guidance
For all query methods, you should be aware of the following arguments:
append- By default, this is set toFalseand so a new query list is created each time you make a new query. Setting it toTrue(i.e. by specifyingappend=True) will result in your newly query results being appended to your previous ones.print- By default, this is set toFalseand so query results will not be printed when you run the query method. Setting it toTruewill result in your query results being printed.
You should also be aware of:
The
.get_minmax_latlon()method, which will print out the minimum and maximum latitudes and longitudes of all your map sheets and can help you identify valid ranges of latitudes and longitudes to use for querying. It’s use is as follows:
my_ts.get_minmax_latlon()
The
.print_found_queries()method, which can be used to print your query results at any time. It’s use is as follows:
my_ts.print_found_queries()
Note
You can also set print=True in the query commands to print your results in situ. See above.
The
.plot_queries_on_map()method, which can be used to plot your query results on a map. As with the.plot_all_metadata_on_map(), you can specifyadd_id=Trueto add the WFS ID numbers to your plot. Use this method as follows:
my_ts.plot_queries_on_map()
Download guidance
Before downloading any maps, you will first need to specify the zoom level to use when downloading your tiles. This is done using:
my_ts.get_grid_bb()
By default, this will use zoom_level=14.
If you would like to use a different zoom level, use the zoom_level argument:
my_ts.get_grid_bb(zoom_level=10)
For all download methods, you should also be aware of the following arguments:
path_save- By default, this is set tomapsso that your map images and metadata are saved in a directory called “maps”. You can change this to save your map images and metadata in a different directory (e.g.path_save="my_maps_directory").metadata_fname- By default, this is set tometadata.csv. You can change this to save your metadata with a different file name (e.g.metadata_fname="my_maps_metadata.csv").overwrite- By default, this is set toFalseand so if a map image exists already, the download is skipped and map images are not overwritten. Setting it toTrue(i.e. by specifyingoverwrite=True) will result in existing map images being overwritten.date_col- The key(s) to use when extracting the publication dates from your metadata.json.metadata_to_save- A dictionary containing information about the metadata you’d like to transfer from your metadata.json to your metadata.csv. See below for further details.
Using the default path_save and metadata_fname arguments will result in the following directory structure:
project
├──your_notebook.ipynb
└──maps
├── map1.png
├── map2.png
├── map3.png
├── ...
└── metadata.csv
By default, your metadata.csv file will only contain the following columns:
“name”
“url”
“coordinates”
“crs”
“published_date”
“grid_bb”
If you would like to transfer additional data from your metadata.json to you metadata.csv, you should create a dictionary containing the names of the fields you would like to save and pass this as the metadata_to_save keyword argument in each download method.
This should be in the form of:
metadata_to_save = {
"new_column_name_1": ["metadata_key_layer_1"],
"new_column_name_2": ["metadata_key_layer_1", "metadata_key_layer_2"],
...
}
For example, to save the “WFS_TITLE” field from the example metadata.json above, you would use:
metadata_to_save = {
"wfs_title": ["properties", "WFS_TITLE"],
}
This would result in a metadata.csv with the following columns:
“name”
“url”
“coordinates”
“crs”
“published_date”
“grid_bb”
“wfs_title”
1. Finding map sheets which overlap or intersect with a polygon.
The .query_map_sheets_by_polygon() and download_map_sheets_by_polygon() methods can be used find and download map sheets which are within or intersect/overlap with a shapely.Polygon.
These methods have two modes:
“within” - This finds map sheets whose bounds are completely within the given polygon.
“intersects” - This finds map sheets which intersect/overlap with the given polygon.
The mode can be selected by specifying mode="within" or mode="intersects".
The .query_map_sheets_by_polygon() and download_map_sheets_by_polygon() methods take a shapely.Polygon object as the polygon argument.
These polygons can be created using MapReader’s create_polygon_from_latlons() function:
from mapreader import create_polygon_from_latlons
my_polygon = create_polygon_from_latlons(min_lat, min_lon, max_lat, max_lon)
e.g. :
#EXAMPLE
my_polygon = create_polygon_from_latlons(54.3, -3.2, 56.0, 3)
Then, to find map sheets which fall within the bounds of this polygon, use:
my_ts.query_map_sheets_by_polygon(my_polygon, mode="within")
Or, to find map sheets which intersect with this polygon, use:
my_ts.query_map_sheets_by_polygon(my_polygon, mode="intersects")
Note
Guidance on how to view/visualize your query results can be found in query_guidance.
To download your query results, use:
my_ts.download_map_sheets_by_queries()
By default, this will result in the directory structure shown in download_guidance.
Note
Further information on the use of the download methods can be found in download_guidance.
Alternatively, you can bypass the querying step and download map sheets directly using the download_map_sheets_by_polygon() method.
To download map sheets which fall within the bounds of this polygon, use:
my_ts.download_map_sheets_by_polygon(my_polygon, mode="within")
Or, to find map sheets which intersect with this polygon, use:
my_ts.download_map_sheets_by_polygon(my_polygon, mode="intersects")
Again, by default, this will result in the directory structure shown in download_guidance.
Note
As with the download_map_sheets_by_queries() method, see download_guidance for further guidance.
1. Finding map sheets which contain a set of coordinates.
The .query_map_sheets_by_coordinates() and download_map_sheets_by_coordinates() methods can be used find and download map sheets which contain a set of coordinates.
To find maps sheets which contain a given set of coordinates, use:
my_ts.query_map_sheets_by_coordinates((x_coord, y_coord))
e.g. :
#EXAMPLE
my_ts.query_map_sheets_by_coordinates((-2.2, 53.4))
Note
Guidance on how to view/visualize your query results can be found in query_guidance.
To download your query results, use:
my_ts.download_map_sheets_by_queries()
By default, this will result in the directory structure shown in download_guidance.
Note
Further information on the use of the download methods can be found in download_guidance.
Alternatively, you can bypass the querying step and download map sheets directly using the download_map_sheets_by_coordinates() method:
my_ts.download_map_sheets_by_polygon((x_coord, y_coord))
e.g. :
#EXAMPLE
my_ts.download_map_sheets_by_coordinates((-2.2, 53.4))
Again, by default, these will result in the directory structure shown in download_guidance.
Note
As with the download_map_sheets_by_queries() method, see download_guidance for further guidance.
3. Finding map sheets which intersect with a line.
The .query_map_sheets_by_line() and download_map_sheets_by_line() methods can be used find and download map sheets which intersect with a line.
These methods take a shapely.LineString object as the line argument.
These lines can be created using MapReader’s create_line_from_latlons() function:
from mapreader import create_line_from_latlons
my_line = create_line_from_latlons((lat1, lon1), (lat2, lon2))
e.g. :
#EXAMPLE
my_line = create_line_from_latlons((54.3, -3.2), (56.0, 3))
Then, to find maps sheets which intersect with your line, use:
my_ts.query_map_sheets_by_coordinates(my_line)
Note
Guidance on how to view/visualize your query results can be found in query_guidance.
To download your query results, use:
my_ts.download_map_sheets_by_queries()
By default, this will result in the directory structure shown in download_guidance.
Note
Further information on the use of the download methods can be found in download_guidance.
Alternatively, you can bypass the querying step and download map sheets directly using the download_map_sheets_by_line() method:
my_ts.download_map_sheets_by_polygon(my_line)
Again, by default, this will result in the directory structure shown in download_guidance.
Note
As with the download_map_sheets_by_queries() method, see download_guidance for further guidance.
4. Finding map sheets using their WFS ID numbers.
The .query_map_sheets_by_wfs_ids() and download_map_sheets_by_wfs_ids() methods can be used find and download map sheets using their WFS ID numbers.
To find maps sheets using their WFS ID numbers, use:
#EXAMPLE
my_ts.query_map_sheets_by_wfs_ids(2)
or
#EXAMPLE
my_ts.query_map_sheets_by_wfs_ids([2,15,31])
Note
Guidance on how to view/visualize your query results can be found in query_guidance.
To download your query results, use:
my_ts.download_map_sheets_by_queries()
By default, this will result in the directory structure shown in download_guidance.
Note
Further information on the use of the download methods can be found in download_guidance.
Alternatively, you can bypass the querying step and download map sheets directly using the download_map_sheets_by_wfs_ids() method:
#EXAMPLE
my_ts.download_map_sheets_by_wfs_ids(2)
or
#EXAMPLE
my_ts.download_map_sheets_by_wfs_ids([2,15,31])
Again, by default, these will result in the directory structure shown in download_guidance.
Note
As with the download_map_sheets_by_queries() method, see download_guidance for further guidance.
5. Finding map sheets by searching for a string in their metadata.
The .query_map_sheets_by_string() and download_map_sheets_by_string() methods can be used find and download map sheets by searching for a string in their metadata.
These methods use regex string searching to find map sheets whose metadata contains a given string.
Wildcards and regular expressions can therefore be used in the string argument.
To find maps sheets whose metadata contains a given string, use:
my_ts.query_map_sheets_by_string("my search string")
e.g. :
#EXAMPLE
my_ts.query_map_sheets_by_string("n?don")
Note
Guidance on how to view/visualize your query results can be found in query_guidance.
Advanced usage
By default the keys argument is set to None, meaning that this method will search for your string in all metadata fields.
You can, however, specify the keys argument to search within a specific metadata field.
e.g. to search in features["properties"]["WFS_TITLE"], you should use keys=["properties", "WFS_TITLE"].
To download your query results, use:
my_ts.download_map_sheets_by_queries()
By default, this will result in the directory structure shown in download_guidance.
Note
Further information on the use of the download methods can be found in download_guidance.
Alternatively, you can bypass the querying step and download map sheets directly using the download_map_sheets_by_string() method:
my_ts.download_map_sheets_by_string("my search string")
e.g. :
#EXAMPLE
my_ts.download_map_sheets_by_string("*shire")
Again, by default, these will result in the directory structure shown in download_guidance.
Note
As with the download_map_sheets_by_queries() method, see download_guidance for further guidance.